I sistemi per l’acquisizione in formato digitale di informazioni tridimensionali di oggetti e superfici sono numerosi ed hanno assunto negli ultimi anni un’importanza sempre più rilevante. Le applicazioni sono le più svariate: controllo dimensionale e di qualità, reverse engineering, automazione, prototipazione rapida, ricostruzione tridimensionale e virtualizzazione. I campi sono i più diffusi: industria, architettura, settore legale, tutela di beni artistici, medicina.
Tra le varie tecniche, quelle che implicano l’utilizzo di sensori ottici, tipicamente non invasivi (privi di contatto diretto), sono quelle che hanno ricevuto il maggior consenso ed interesse: il tempo di acquisizione, rispetto alle soluzioni con sonde “a contatto”, è notevolmente minore. Inoltre vengono evitati l’usura e l’eventuale danneggiamento dello strumento e della superficie in analisi.
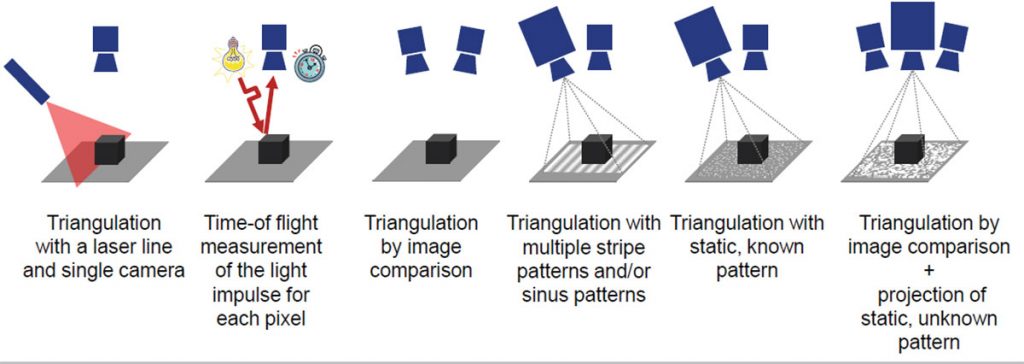
Le tecniche ottiche possono essere distinte in due grandi gruppi: tecniche passive e tecniche attive.
Con i metodi passivi non è necessario un controllo sulla sorgente di luce: il più grosso svantaggio e rappresentato dal notevole aggravio computazionale per l’elaborazione dei dati e l’ottenimento dell’informazione di profondità. Nei metodi attivi, invece, l’uso di luce strutturata (con un preciso pattern) semplifica di molto questo problema.
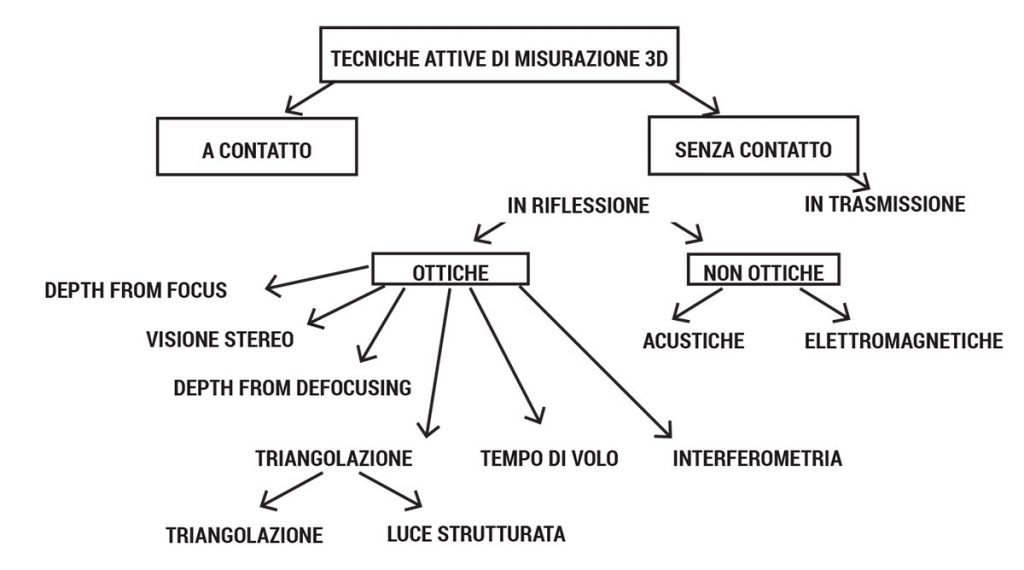
Nell’ultimo decennio si è assistito alla diffusione di sensori che, sfruttando differenti tecnologie, consentono di acquisire informazioni tridimensionali.
Tali sistemi di acquisizione operano secondo principi di funzionamento diversi; essi sono la triangolazione, la misura del tempo di volo o altre proprietà fisico-geometriche.
DEPTH FROM FOCUS
La tecnica DEPTH FROM FOCUS (DFF) permette la ricostruzione delle informazioni 3D di una superficie da diverse immagini prese a diverse distanze di messa a fuoco tra la telecamera e l’oggetto. Essa consente, in maniera estremamente precisa, di effettuare misure 3D non distruttive di superfici.
È possibile ricostruire la superficie di un oggetto 3D sapendo che i punti di un oggetto si trovano a diverse distanze dalla telecamera e la telecamera ha una limitata profondità di campo.
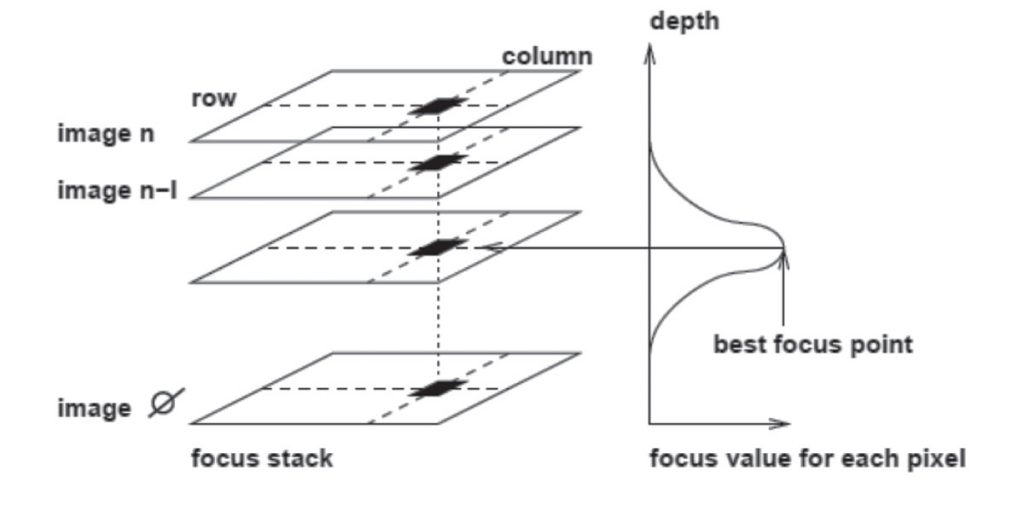
A seconda della distanza e della messa a fuoco, i punti dell’oggetto vengono visualizzati più o meno nettamente nell’immagine, cioè solo quei pixel posti entro una “distanza corretta” dalla telecamera risultano a fuoco. Prendendo immagini a diverse distanze dall’oggetto, potremo osservare come ciascun punto dell’oggetto risulterà a fuoco almeno in una di tali immagini. Questa sequenza di immagini viene chiamata “focus stack”. Determinando in quale immagine un punto dell’oggetto è a fuoco, è possibile calcolare la distanza di ciascun punto dalla telecamera.
Le tecniche ottiche possono essere distinte in due grandi gruppi: tecniche passive e tecniche attive.
Con i metodi passivi non è necessario un controllo sulla sorgente di luce: il più grosso svantaggio e rappresentato dal notevole aggravio computazionale per l’elaborazione dei dati e l’ottenimento dell’informazione di profondità. Nei metodi attivi, invece, l’uso di luce strutturata (con un preciso pattern) semplifica di molto questo problema.
Questa figura mostra la pila fuoco delle immagini sul lato sinistro e il valore corrispondente di fuoco che viene determinato per ciascun pixel – sul lato destro. Il miglior punto focale è l’immagine in cui un pixel ha la massima nitidezza
La profondità di campo (DOF) è l’intervallo di distanza entro il quale l’immagine è nitida rispetto al miglior punto focale, che è il punto con perfetta nitidezza dell’immagine. Una bassa profondità di campo significa che solo una piccola fetta dell’oggetto è ripresa nettamente mentre una elevata profondità di campo significa che una grande parte o forse l’intera immagine è nitida. Nella tecnica DFF, una bassa profondità di campo porta ad una maggiore precisione.
Tuttavia, questa precisione necessita di un tempo di esecuzione molto lungo a causa del numero di immagini che devono essere processate. Generalmente parlando, più immagini devono essere elaborate, maggiore è la precisione, più lungo è il tempo di esecuzione.
La tecnica DFF permette una misurazione 3D ad alta precisione. Ha dimostrato di essere molto utile nella microscopia (piccoli oggetti che vengono ingranditi più di una volta) ed è spesso più facile da realizzare rispetto ad altri metodi. In molti casi, il sistema risulta essere più compatto rispetto ad un sistema stereo che necessita di molto spazio a causa dell’utilizzo di due telecamere. La scelta di un obiettivo adatto (solitamente telecentrico) è molto importante, e questo è spesso un vantaggio utilizzando un’unica telecamera.
Per piccoli oggetti di dimensioni più piccole di una decina di millimetri, i sistemi a triangolazione laser potrebbero diventare molto costosi a causa della linea del laser sottile necessaria e meno precisi a causa di possibili riflessioni.
I sistemi stereo fotometrici di solito sono più precisi e più facili da realizzare per oggetti piatti senza ripidi spigoli geometrici. Per le misurazioni macroscopiche (Campo di misura fino a 100 mm), sistemi stereo o a triangolazione sono più veloci in quanto richiedono meno immagini.
Un’altra tecnica di misurazione di superfici 3D, simile al DFF, è la DEPTH FROM DEFOCUSING (DFD). Questa tecnica richiede un immagine nitida in primo piano e una immagine nitida di sfondo. La distanza di tutti i punti che si trovano tra il primo piano e lo sfondo viene interpolato dalla loro quantità di sfocatura. Poiché dipende solo due immagini, può essere più veloce, ma non è precisa come la tecnica DFF.
SISTEMA LIDAR
La tecnologia Lidar ha applicazioni in geologia, sismologia, archeologia, rilevamento remoto e fisica dell’atmosfera.

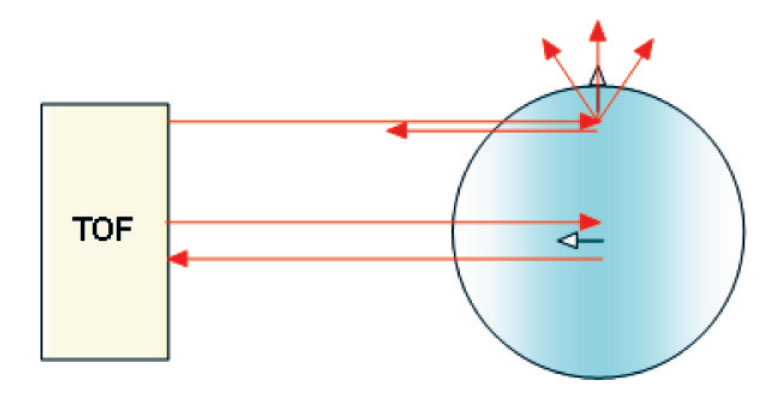
Come per il radar, che al posto della luce utilizza onde radio, la distanza dell’oggetto è determinata misurando il tempo trascorso fra l’emissione dell’impulso e la ricezione del segnale retro diffuso ( TOF). La sorgente di un sistema LIDAR è un laser, ovvero un fascio coerente di luce ad una precisa lunghezza d’onda, inviato verso il sistema da osservare. Il sistema LIDAR usa lunghezze d’onda ultraviolette, nel visibile o nel vicino infrarosso; questo rende possibile localizzare e ricavare immagini e informazioni su oggetti molto piccoli, di dimensioni pari alla lunghezza d’onda usata. Perciò il lidar è molto sensibile agli aerosol e al particolato in sospensione nelle nuvole ed è molto usato in meteorologia e in fisica dell’atmosfera.
Affinché un oggetto rifletta un’onda elettromagnetica, deve produrre una discontinuità dielettrica; alle frequenze del radar (radio o microonde) un oggetto metallico produce una buona eco, ma gli oggetti non-metallici come pioggia e rocce producono riflessioni molto più deboli, e alcuni materiali non ne producono affatto, risultando invisibili ai radar. Questo vale soprattutto per oggetti molto piccoli come polveri, molecole e aerosol.
I laser forniscono la soluzione: la coerenza e densità del fascio laser è ottima, la lunghezza d’onda è molto più breve dei sistemi radio, e va dai 10 micron a circa 250 nm. Onde di questa lunghezza d’onda sono riflesse bene dai piccoli oggetti, con un comportamento detto retrodiffusione.
I sistemi lidar aerei sono usati per il rilevamento di faglie, subsidenza e altri movimenti geologici, per monitorare i ghiacciai, nella silvicoltura, nel controllo della velocità dei singoli veicoli, in ambito militare la loro maggiore risoluzione li rende particolarmente adatti a ricavare immagini tanto dettagliate da permettere di riconoscere il tipo esatto di bersaglio.
TECNOLOGIA TEMPO DI VOLO
I sensori basati sul tempo di volo utilizzano una tecnologia esistente da vari anni, tuttavia si sono diffusi nel mercato consumer soltanto negli ultimi tempi dopo una sensibile riduzione dei costi di produzione.
I sensori calcolano la distanza fra la sorgente e la superficie che si desidera misurare calcolando il tempo che la sorgente luminosa puntiforme impiega per arrivare sulla superficie del sensore. Gli impulsi luminosi sono segnali infrarossi inviati tramite una sorgente di luce modulata e il ricevitore è una matrice di sensori CCD/CMOS.
La misurazione viene eseguita in maniera indipendente per ogni pixel della telecamera, permettendo di acquisire interamente la scena inquadrata.
Le telecamera TOF (Time Of Flight) che si basano su questo principio sono in genere caratterizzate da una risoluzione di alcune migliaia di pixel e da un range di misura che varia da alcune decine di centimetri ad un massimo di 30 metri. Queste telecamera sono in grado di fornire in tempo reale l’insieme dei punti (x, y, z), l’immagine di prossimità, l’immagine di ampiezza e l’immagine di intensità.
VANTAGGI:
- È un sistema compatto dal basso costo che non richiede particolari operazioni di installazione, al contrario di altri sistemi con maggiore accuratezza come gli scanner laser.
- Fornisce direttamente una mappa di profondità, al contrario di telecamere stereo per le quali devono essere eseguiti algoritmi particolari per il calcolo della disparità e la triangolazione.
- Effettua la misurazioni di tutta la scena inquadrata in tempo reale; esegue tutti i calcoli utilizzando il microprocessore interno in maniera molto rapida ed efficiente, dando la possibilità di restituire solo i risultati tramite interfacce diffuse (USB o Fast Ethernet). Non richiede pertanto particolari requisiti per il computer a cui è collegato.
- E una tecnologia più robusta ai cambiamenti di luce rispetto ad altri sensori come le telecamere stereo.
SVANTAGGI
- La scarsa risoluzione permette di ricavare un’informazione limitata sulla geometria della scena e sulle superfici presenti.
- Per materiali poco riflettenti (ad esempio una stoffa) o di colore scuro non è possibile ottenere misure accurate causa il debole segnale di ritorno.
- Si possono verificare sbilanciamenti nelle rilevazioni causa errate disposizioni del sensore o angoli di inquadratura. Il “multipath error” è un esempio: nel caso di una scena con geometrie concave (due parenti incidenti), il segnale luminoso colpisce una parete, ma il segnale riflesso colpisce la seconda parete prima di essere diretto verso il sensore. In questo caso, la distanza della parete rilevata risulta maggiore rispetto a quella reale.
- La rilevazione della distanza lungo i bordi di superfici risulta imprecisa. I punti appartenenti a superfici che presentano un angolo di curvatura troppo ampio con la direzione della camera sono affetti da scarsa affidabilità nella stima della loro distanza. In questi tratti il segnale luminoso viene riflesso in più direzioni e il ricevitore rileva solo una parte del segnale di ritorno; questa difficoltà fisica unita alla risoluzione limitata, costringe il sensore TOF a generare un valore di profondità unico per più particolari dell’immagine.
- Sorgenti luminose esterne come il sole possono interferire con il segnale del sensore, generando errori in fase di ricezione.
Attenuazione e riessione del segnale IR sui bordi di un oggetto.
Attenuazione e riessione del segnale IR sui bordi di un oggetto
TRIANGOLAZIONE LASER
Il laser è un dispositivo in grado di emettere un fascio di luce coerente, monocromatica e, con alcune eccezioni, concentrata in un raggio rettilineo estremamente collimato attraverso il processo di emissione stimolata. Inoltre la luminosità delle sorgenti laser è molto elevata paragonata a quella delle sorgenti luminose tradizionali. Queste tre proprietà (coerenza, monocromaticità e alta luminosità) sono alla base del vasto ventaglio di applicazioni che i dispositivi laser hanno avuto e continuano ad avere nei campi più disparati, tra i quali anche l’acquisizione di dati di prossimità.
Nei sensori basati su triangolazione laser il fascio dell’illuminatore laser viene proiettato sull’oggetto da osservare da una determinata posizione, mentre un sensore rileva la componente riflessa. Conoscendo le posizioni relative e gli orientamenti del sensore e del laser insieme al modello geometrico si riesce a determinare la posizione in coordinate tridimensionali del punto illuminato.
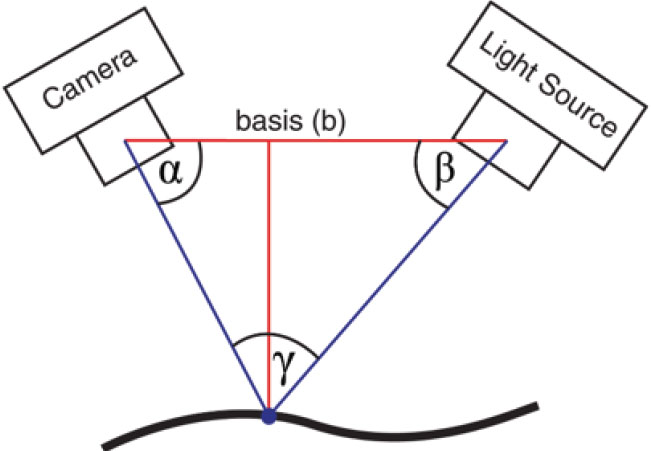
Principio di funzionamento della triangolazione laser a singolo punto
L’evoluzione più immediata del singolo punto, ottenuto con un raggio di luce, e la proiezione di una linea, ottenuta con un piano di luce. L’intersezione del piano di luce con la superficie dell’oggetto è utilizzata al fine di rivelarne il profilo. In questo modo e possibile calcolare simultaneamente i valori di profondità di un più ampio insieme di punti da una singola immagine, velocizzando ulteriormente il processo di acquisizione rispetto alla semplice proiezione di un unico punto.
La telecamera esegue le misurazioni sull’asse di movimento y osservando la proiezione dell’illuminatore laser sull’oggetto lungo l’asse x e calcolandone l’altezza per tutta la sua larghezza. Per esempio, presa una telecamera con risoluzione 1920×1200, supponendo di utilizzare la massima risoluzione orizzontale, quindi 1920, e 512 righe in verticale (1920 x 512 pixel), la telecamera acquisirà 512 profili ed ognuno di essi conterrà 1920 valori che stanno ad indicare l’altezza dell’oggetto ad un determinato punto (x,y). L’unione dei profili costituisce un’immagine di prossimità (detta disparity), in cui la x e la y, indici di colonna e di riga, identificano una posizione mentre il valore del pixel corrispondente identifica una valore di altezza(z).
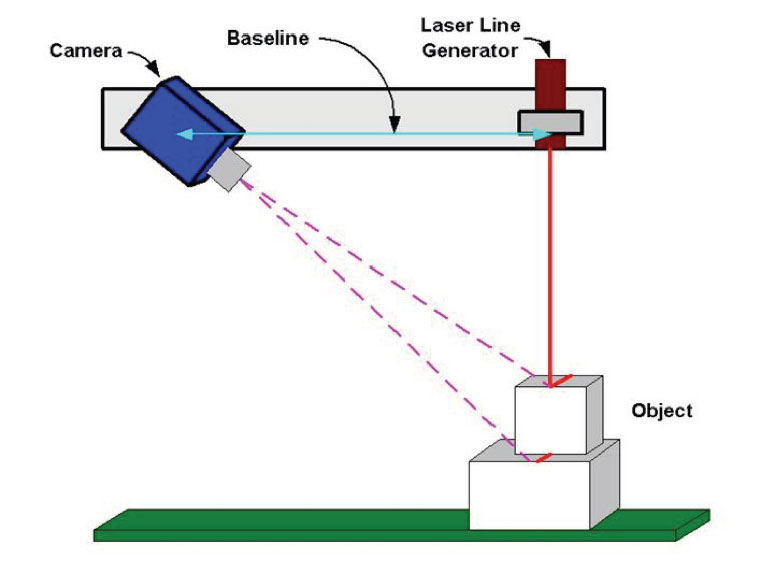
Vi sono varie configurazioni geometriche che è possibile adottare attraverso la diversa disposizione della telecamera e del laser fra di loro. Le principali geometrie che si possono adottare sono quattro rappresentate dalle seguenti figure:


Problemi con cui ci si scontra utilizzando questa tecnologia:
1. Occlusione: si verifica quando la linea proiettata dall’illuminatore laser non è visibile dalla telecamera.
Questo può accadere per due motivi:
- occlusione del laser: il laser non riesce fisicamente ad illuminare una parte dell’oggetto;
- occlusione della telecamera: quando una parte della linea del laser non è visibile dalla telecamera poiché l’oggetto stesso la occlude.
2. Riflessione/Assorbimento: quando si fanno delle misurazioni su degli oggetti bisogna tener conto anche delle riflessioni prodotte dalla luce del laser. Un oggetto illuminato può riflettere la luce in diverse direzioni, per riflessione diretta o diffusa. Se parte della luce non viene riflessa, può essere assorbita dal materiale, oppure può essere trasmessa attraverso l’oggetto.
Il range massimo delle misurazioni è il rapporto tra il punto più alto e quello più basso misurabile all’interno di una ROI (Region Of Interest). Avere un range massimo elevato significa avere la possibilità di misurare oggetti che variano anche di molto in altezza. La risoluzione di range è la minima variazione d’altezza che è possibile misurare. Quindi avere un’alta risoluzione significa che si possono misurare le piccole variazioni d’altezza ma anche che il range massimo misurabile sarà piccolo rispetto a quello di una bassa risoluzione con la stessa ROI. In generale il range massimo e la risoluzione dipendono dall’angolo fra la telecamera ed il laser. Se questo angolo è piccolo si ha che la linea del laser non varia molto nell’immagine del sensore anche se l’oggetto varia molto in altezza; questo si traduce con un elevato range massimo misurabile ma ad una bassa risoluzione, con poca occlusione. Invece se l’angolo è grande allora si avrà che anche piccole variazioni d’altezza spostano la linea del laser anche di diversi pixel all’interno dell’immagine del sensore e questo si traduce con un basso range massimo ma un’alta risoluzione
Vantaggi:
- Misure a grande distanza dal target.
- Spot minuto adatto a piccoli target.
- Alta precisione.
- Possibilità di misurare quasi tutti i tipi di materiale.
- Indipendenza dalla luce ambientale.
Inoltre la possibilità di misurare a distanza, consente a questi sensori di operare con target difficili (come ad esempio metalli roventi oppure pneumatici).
Svantaggi:
- potenziali rischi per l’occhio umano, dipendenti dalla classe del laser utilizzato;
- dipendenza delle prestazioni dal tipo di materiale illuminato. Le riflessioni speculari di oggetti metallici, per esempio, possono creare un disturbo e degradare le prestazioni del sistema.
- Il sistema deve prevedere la movimentazione dell’oggetto o della componente laser/camera con un incremento dei costi nella realizzazione meccanica.
VISIONE 3D IN CAMPO CHIARO
La visione stereo è ben nota e ampiamente usato per molti applicazioni di immagini 3D. Un approccio simile alla visione Stereo è l’approccio di misura in campo chiaro (light-field measurement approach).
Una telecamera plenottica è una tipologia di telecamera che utilizza una matrice di microlenti per catturare informazioni in 4D sul campo luminoso di una scena. Essa registra non solo l’intensità della luce, ma la combinazione di intensità luminosa e direzione di incidenza dei raggi di luce. Questo in contrasto con una telecamera convenzionale che registra solamente l’intensità della luce. Una telecamera plenottica, a differenza dei sistemi di stereo visione, restituisce informazioni 3D di una scena con una sola telecamera, una sola lente acquisendo una sola immagine. Questo è possibile ponendo un array di microlenti direttamente di fronte al sensore. La stima della profondità è basata sulla disparità osservata per ogni singola immagine vista da ogni singola microlente, processo simile all’approccio con stereo visione. Per relazionare la profondità virtuale all’unità di misura reale, la telecamera deve essere calibrata.
Non è necessario solamente trovare la relazione tra la profondità virtuale e la profondità in unità metrica ma è anche necessario rettificare ogni distorsione geometrica introdotta dalla lente principale, cosa che potrebbe influire nella valutazione corretta della misura.
Con una telecamera plenottica, è possibile generare contemporaneamente un’immagine in campo chiaro e un corrispondente mappa di profondità. Una volta che la mappa di profondità è nota, l’immagine di intensità può essere riorientata per aumentarne la profondità di campo.
Nelle telecamere plenottiche prodotte dalla società Raytrix, una matrice di microlenti (MLA) è posta direttamente di fronte al sensore; il posizionamento delle microlenti si può osservare nella figura seguente.
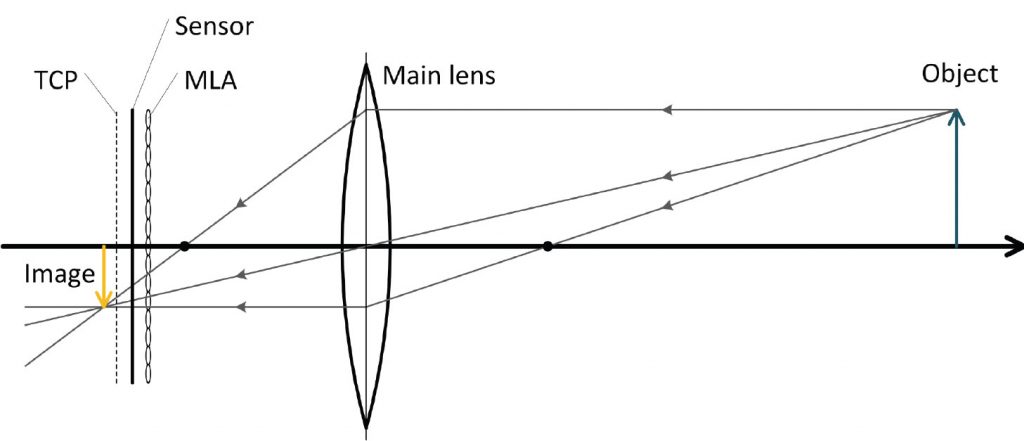
Il piano di copertura totale (TCP) è il piano su cui la lente principale deve essere messo a fuoco.
Se la proiezione della lente principale è più vicina al sensore, non è possibile avere una stima della profondità. Quando la matrice di microlenti è posta alla corretta distanza dal sensore, le microlenti proietteranno piccole sotto-immagini sul sensore. Ognuna di queste sotto-immagini mostra una vista leggermente diversa di l’oggetto. Quando un punto di un oggetto viene visto in almeno due sotto-immagini, può essere stimata la cosiddetta profondità virtuale del punto oggetto. Questa stima della profondità funziona in modo simile all’approccio nella stereo visione.
STEREO FOTOMETRICA
L’idea è partire dall’immagine di un oggetto illuminato, cercando di ricostruire la sua struttura tridimensionale tramite l’ombreggiatura. Tale problema è noto alla comunità scientifica come il problema di “Shape from Shading” (forma dall’ombreggiatura). Da diversi studi effettuati si è concluso che non è possibile ricavare la superficie 3D di un oggetto utilizzando una sola immagine tramite l’approccio dello Shape from Shading.
La tecnica fotometrica è basata sullo “Shade from Shading” ma utilizza immagini multiple ottenute cambiando la direzione di illuminazione dell’oggetto: algoritmi ricostruiscono l’orientamento delle normali di una superficie da più immagini (minimo 3) acquisite da una posizione fissa variando le condizioni di illuminazione. Molti di questi algoritmi richiedono che le condizioni di illuminazione e la relazione spaziale tra le sorgenti di illuminazione e la telecamera vengano registrate durante l’acquisizione dei dati in modo tale da poter determinare in modo univoco la direzione delle normali.
Ne risulta una mappa dei gradienti e una mappa delle normali che ci consentono di stabilire l’orientazione punto per punto dell’oggetto che può essere poi in un secondo momento utilizzata per ricostruire la superficie stessa.
L’andamento superficiale dell’oggetto inquadrato può essere utilizzato per guidare le successive fasi di processo industriale e generare azioni automatizzate.
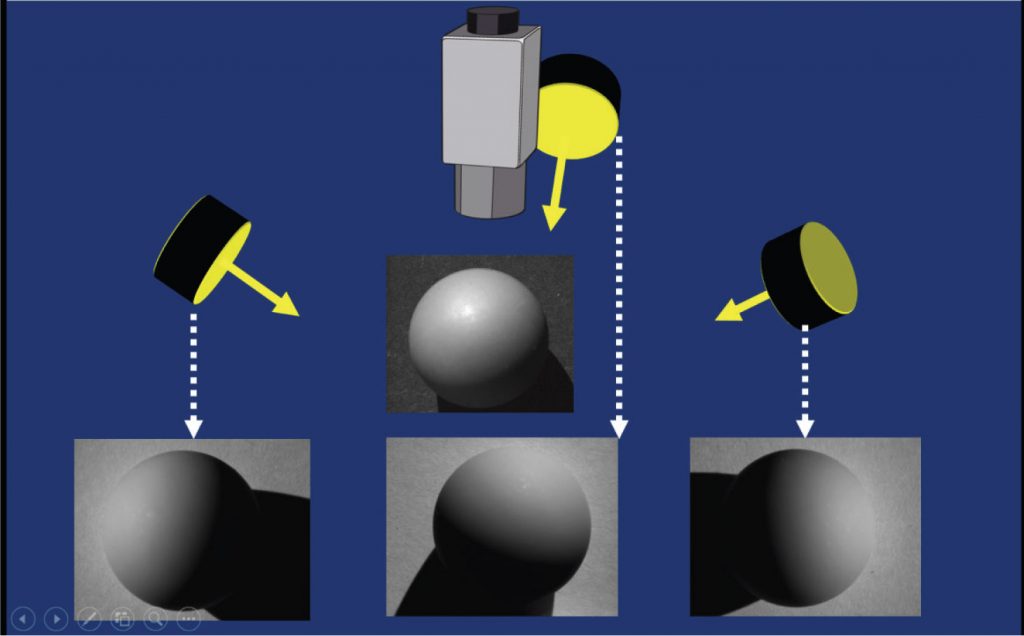
Notare che l’immagine ‘altezza’ finale ottenuta riflette solamente delle altezze relative, ovvero con un sistema fotometrico non è possibile effettuare una ricostruzione 3D calibrata.
I vantaggi per il mondo industriale sono:
- necessita di una sola telecamera, dunque riduce i costi e la complessità computazionale dello stereo matching tradizionale;
- può essere utilizzata con materiali non idonei alla visione stereo e anche in assenza di texture; in altre parole, restituisce informazioni sull’oggetto qualitativamente molto alte, “quasi 3D”, con costi estremamente più contenuti e per svariate applicazioni di controllo qualità di oggetti con superfici piane (individuazione di graffi, difetti superficiali, identificazione di curvature e integrità, lettura di caratteri in rilievo).

Rilevamento di un difetto sulla superficie di una bottiglia di shampoo

Rilevamento caratteri
Un esempio di applicazione è il rilevamento di difetti su superfici piane.
Gli svantaggi sono:
- un’area inquadrata ristretta;
- l’utilizzo di ottiche telecentriche e di illuminatori collimati.
Una serie di limiti piuttosto importanti che a volte incidono pesantemente nella ricostruzione 3-D delle superfici. Prima fra tutte le proprietà fisiche degli oggetti, infatti per ottenere buoni risultati, quest’ultimi dovrebbero essere molto regolari, quindi caratterizzati da geometrie non troppo complesse, poco spigolose, e caratterizzate da materiali altamente riflettenti. Da non trascurare il contesto in cui sono situati i nostri oggetti, infatti il background deve essere il più uniforme possibile, l’ideale sarebbe l’utilizzo di uno sfondo nero tale da evidenziare le caratteristiche geometriche dell’oggetto. Non sempre però tutte queste specifiche possono essere soddisfatte.
Tutti questi fenomeni di non idealità si riflettono sulla propagazione degli errori.

VISIONE STEREOSCOPIC
La visione stereoscopica consente di osservare la struttura tridimensionale di una scena osservata da due o più telecamere.
Il principio alla base della visione stereoscopica consiste in una triangolazione mirata a mettere in relazione la proiezione di un punto della scena sui due (o più) piani immagine delle telecamere (e.g. tali punti sono denominati punti omologhi) che compongono il sistema di visione stereoscopico.
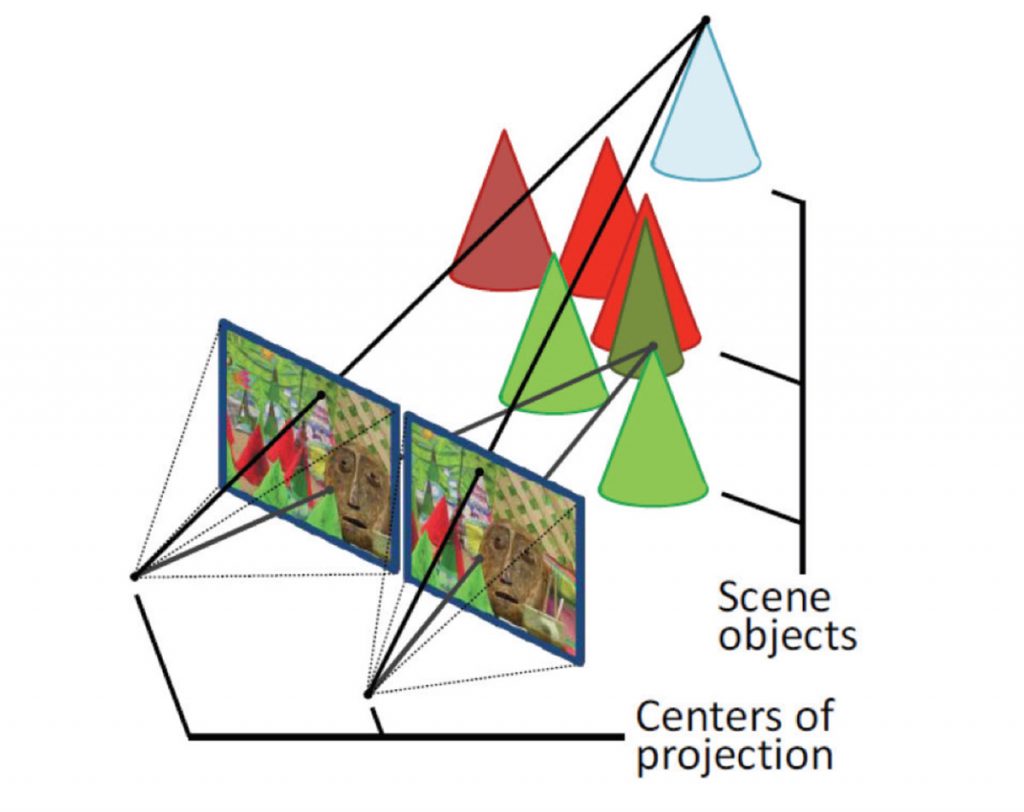
L’individuazione dei punti omologhi, problema noto in letteratura come il problema della corrispondenza (correspondence problem o matching stereo), consente di ottenere una grandezza denominata disparità (disparity), che rappresenta la differenza di posizione dei due punti omologhi nelle due immagini, mediante la quale, conoscendo opportuni parametri del sistema stereoscopico, è possibile risalire alla posizione 3D del punto considerato.
I problemi da affrontare in un sistema basato sulla visione stereo sono :
1. riduzione significativa della similarità nella scena osservata dalle due o più telecamere
Distorsioni fotometriche
1.1 punti corrispondenti avranno luminosità differente a causa del differente punto di vista.
1.2 Differenze nei parametri che caratterizzano la risposta delle due telecamere.
1.3 Rumore.
Distorsioni prospettiche
1.4 A causa della differente prospettiva regioni corrispondenti possono apparire di dimensioni differenti nelle due immagini.
2. Occlusioni: a causa della diversa posizione delle telecamere che compongono un sistema di visione stereoscopico nello spazio è possibile che un punto non risulti proiettato su tutti i piani immagini delle telecamere. In tal caso il problema delle corrispondenze non ha soluzione e non è possibile determinare la distanza del punto esaminato dalle telecamere e quindi se i punti non bastano sarà necessario utilizzare una metodologia differente.
Ad esempio è possibile l’utilizzo di più telecamere in grado di acquisire la stessa scena da più punti di vista e la combinazione delle diverse nuvole di punti ottenute in un unico modello 3D finale.

3. Regioni con poca texture e pattern periodici: se la scena non presenta differenze che si possono discrimanere è necessario ad esempio generare texture addizionali sulla superficie dei campioni tramite l’ausilio di proiettori integrati o esterni al dispositivo.
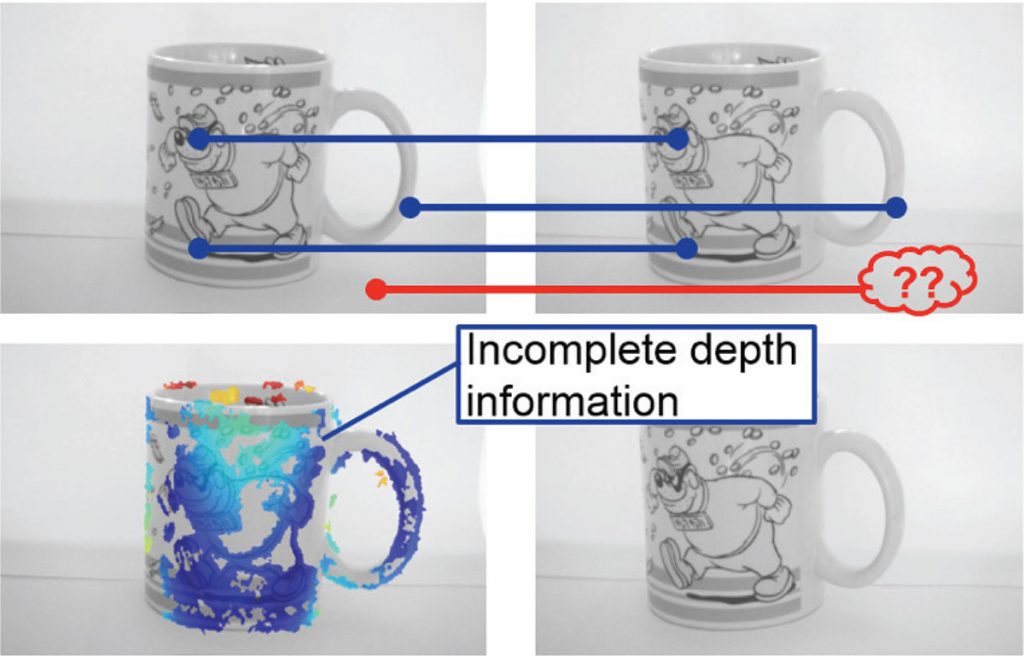

I vantaggi principali nell’utilizzo della sterovisione è la possibilità di controllare il costo del sensore scegliendo ed utilizzando telecamere standard disponibili sul mercato. Questo tipo di tecnica prevede l’utilizzo di sensori passivi, quindi può sfruttare l’illuminazione dell’ambiente. Inoltre non prevede l’utilizzo di parti meccaniche in movimento riducendo i costi di realizzazione del sistema.
Gli svantaggi maggiori di questa tecnologia sono la necessità di sincronizzare l’acquisizione delle immagini tra tutte le telecamere del sistema e quella di calcolare i punti omologhi, che risulta essere un’operazione computazionalmente costosa e quindi non utilizzabile per applicazioni real-time.
Inoltre i risultati forniti da questi sensori dipendono dalla tessitura delle immagini utilizzata nel calcolo dei punti omologhi, ad esempio uno sfondo uniforme è difficilmente individuabile.
Pertanto questi sensori, oltre ad avere un range di misura limitato, offrono un’accuratezza solitamente limitata, una risoluzione variabile, una precisione bassa della misura e un tempo di risposta medio.
Le applicazioni che meglio si adattano a questa tecnica sono la localizzazione, identificazione nonché ispezione e misura.